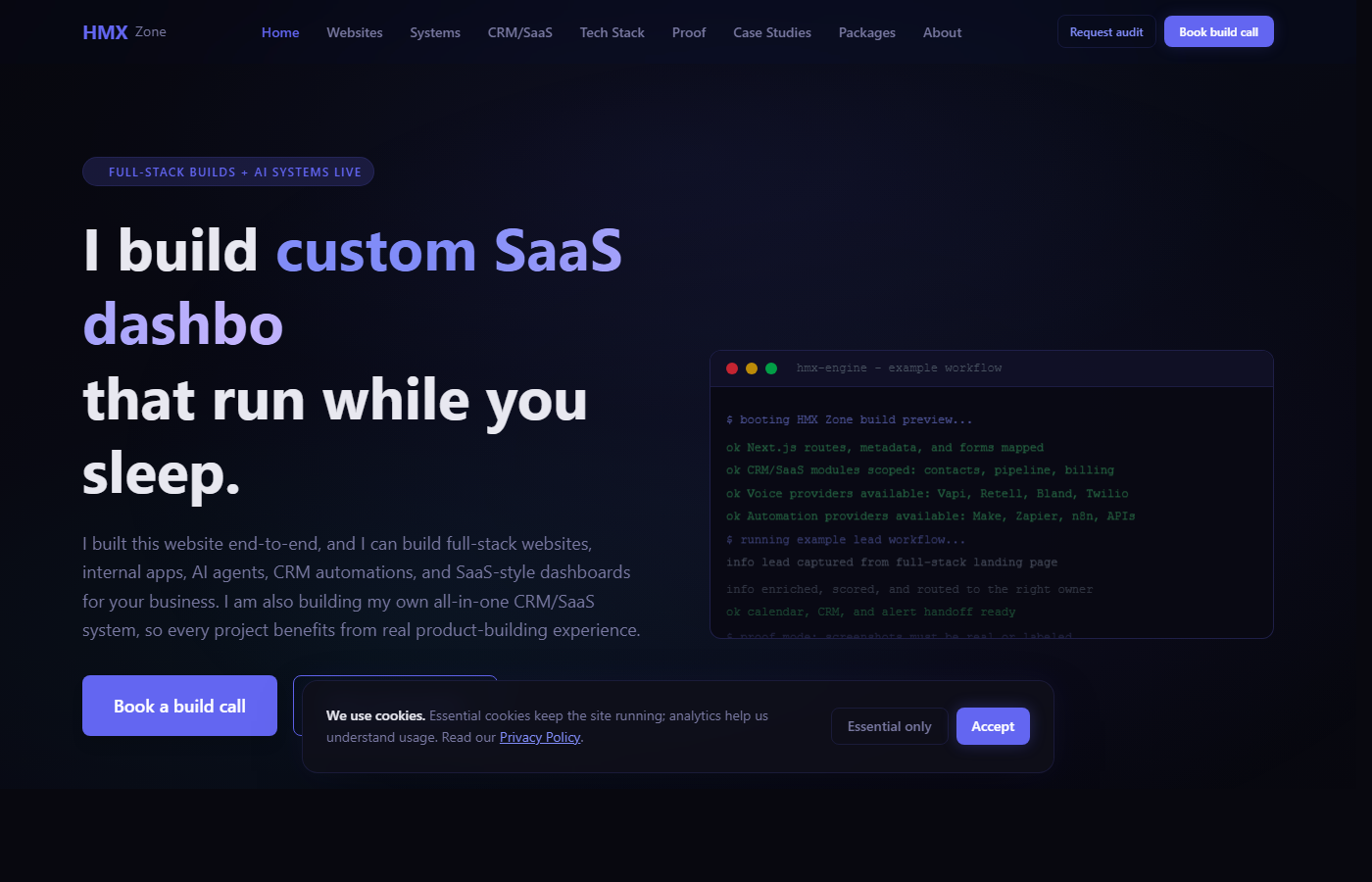
Verified proof
HMX Zone full-stack website screenshot
The public site itself is the verified full-stack website proof artifact.
- Next.js
- React
- TypeScript
- Supabase-ready forms
- Vercel
Real site, architecture, and build artifacts, staged around the parts that make the website operate.
Proof
Real build proof for this service — workflow screenshots and architecture diagrams.
Verified proof
The public site itself is the verified full-stack website proof artifact.

Verified proof
A route and data-flow diagram for the public website, intake form, analytics, proof, and case-study structure.
A route assembles through form, data, metadata, and deploy checks.
Route map
Clear service routes
Lead capture
Lead capture that saves context
Public metadata
SEO and schema on public pages
Launch QA
Analytics events tied to CTAs